
CluedIn Data Fabric
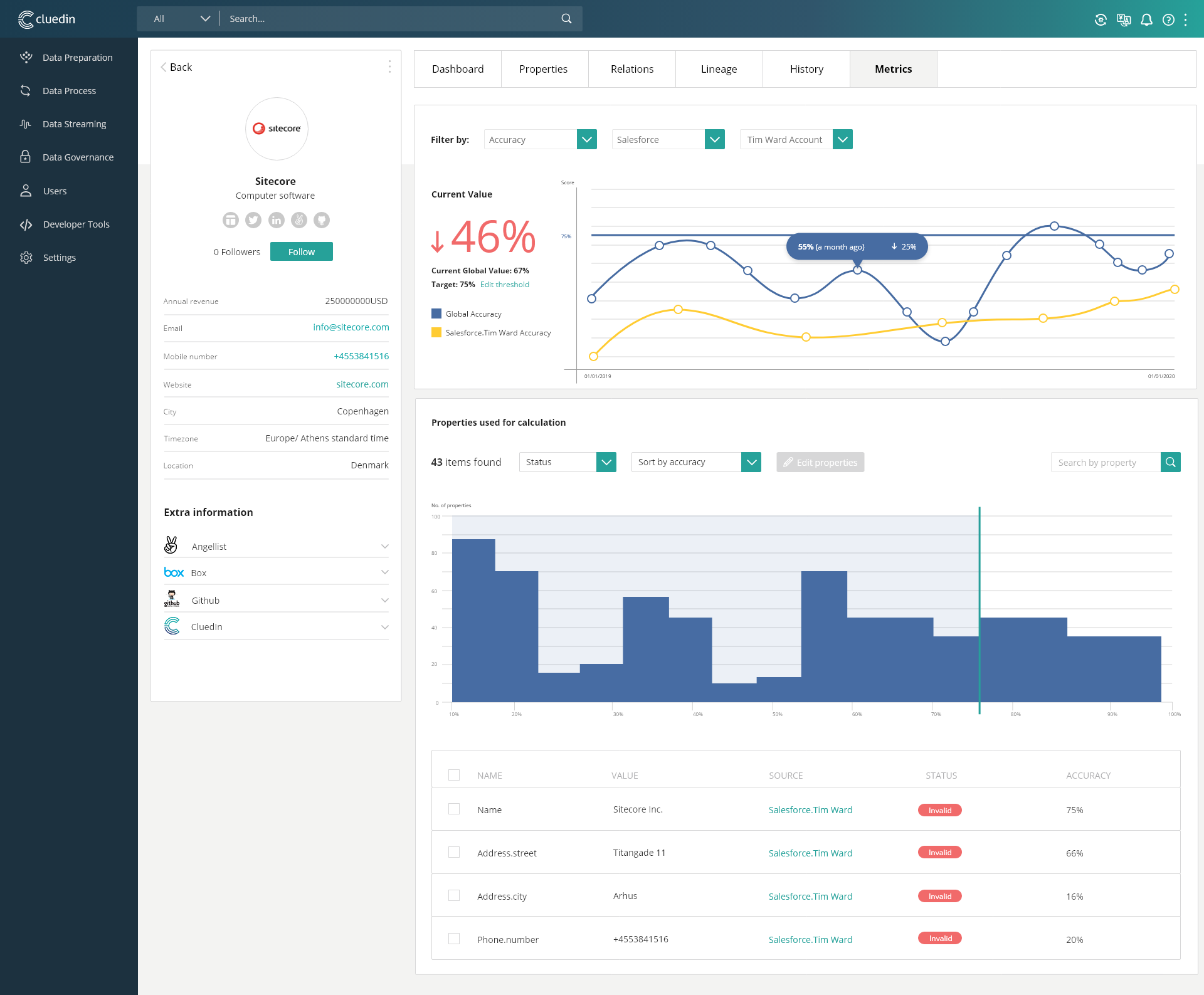
CluedIn provides a foundation of data infrastructure to provide
reliable, secure, scalable and trustworthy data to fuel any
data-driven project.
CluedIn streamlines the process of making data ready to use and
provides you with the key pillars of data management

Data Integration. Reinvented.
Automate Data Integration.
We provide an integration platform that does all the joining of
records for you. Forget complex designers and ETL pipelines.... you
don't need them.
A pattern that supports endless data sources.
You will never stop growing. Your company will bring on more systems, generate more data and need to move faster. CluedIn's integration pattern paves the way for flexible and scalable data integration.
- You can take one tool at a time, integrating tool 1 is as easy as tool 301.
- No need for domain experts to sit together and map systems.
- No need for expensive data engineers to build complex pipelines.
- The pattern will find more connections than you can with other tools.
- The pattern is simpler, better, easier to understand and you will never go back to your old ways.
- Dynamic schema recognition and correction of schema drifts
Ready to go.
Time to value has never been this quick.
CluedIn is designed to take data at its face value. We don't need
or want you to clean or prepare data for CluedIn. CluedIn utilises
an ELT approach to simply load data from systems as is. We take
care of the rest.
- 220+ Connectors.
- Support for Cloud or On-Premise or a hybrid.
- Support for CDC, Batch, Streaming, Push.
- Active Metadata Driven Integration.
- Can integrate into existing ETL Pipelines like Informatica, SSIS, Data Factory, SAP, Nifi and more.
Data Integration solved for good.
There are so many ways to integrate data and CluedIn makes sure that this is all abstracted away from you. What matters for you is that you want data ready-to-use, don't get lost in all the ways to deliver that - that's CluedIn's job.
- Access to Multiple Data Sources
- Structured, Semi-Structure and Unstructured Data Support
- EDI, Swift and HL7 Support
- Active Metadata Support
- Bulk/Batch Data Movement
- Data Preparation and Usability
- Data Replication and Synchronization
- Data Virtualization
- Message-Oriented Data Movement
- Passive Metadata Support
- Scalability and Performance
- Stream Data Integration
Built for scale.
Throw anything at CluedIn.
CluedIn was designed to support structured, semi-structures and
unstructured data and lots of it. It is not unfamiliar for CluedIn
to process 100's of TB's of data.
- Unlimited Data Connectors and amount of data, no cost per MB or consumption cost.
- Fast.....really fast.
- TB and PB scale.
Resilient and Robust
Guaranteed Delivery.
Data needs to get from A to B. Many things can go wrong in that
process, but that shouldn't be your burden. CluedIn is backed by
robust and reliable infrastructure so data will find its way in the
world.
- Schema-Drift-Proof
- Robust Data Delivery Guarantee
- Buffering, Back-Pressure
- Verbose Monitoring, Metrics and Telemetry
Client: CluedIn
Project link
